
Innovation requires collaboration, but due to the current state of our filter bubbles, collaboration is stuck in a rut. Data science utilizing knowledge graphs and team and portfolio optimization software can help us climb out. It can increase the scale, the intentionality, and the nuance of how we collaborate. With the right data and algorithms, we can use software to optimize our teams and facilitate innovation.
The Innovation Problem
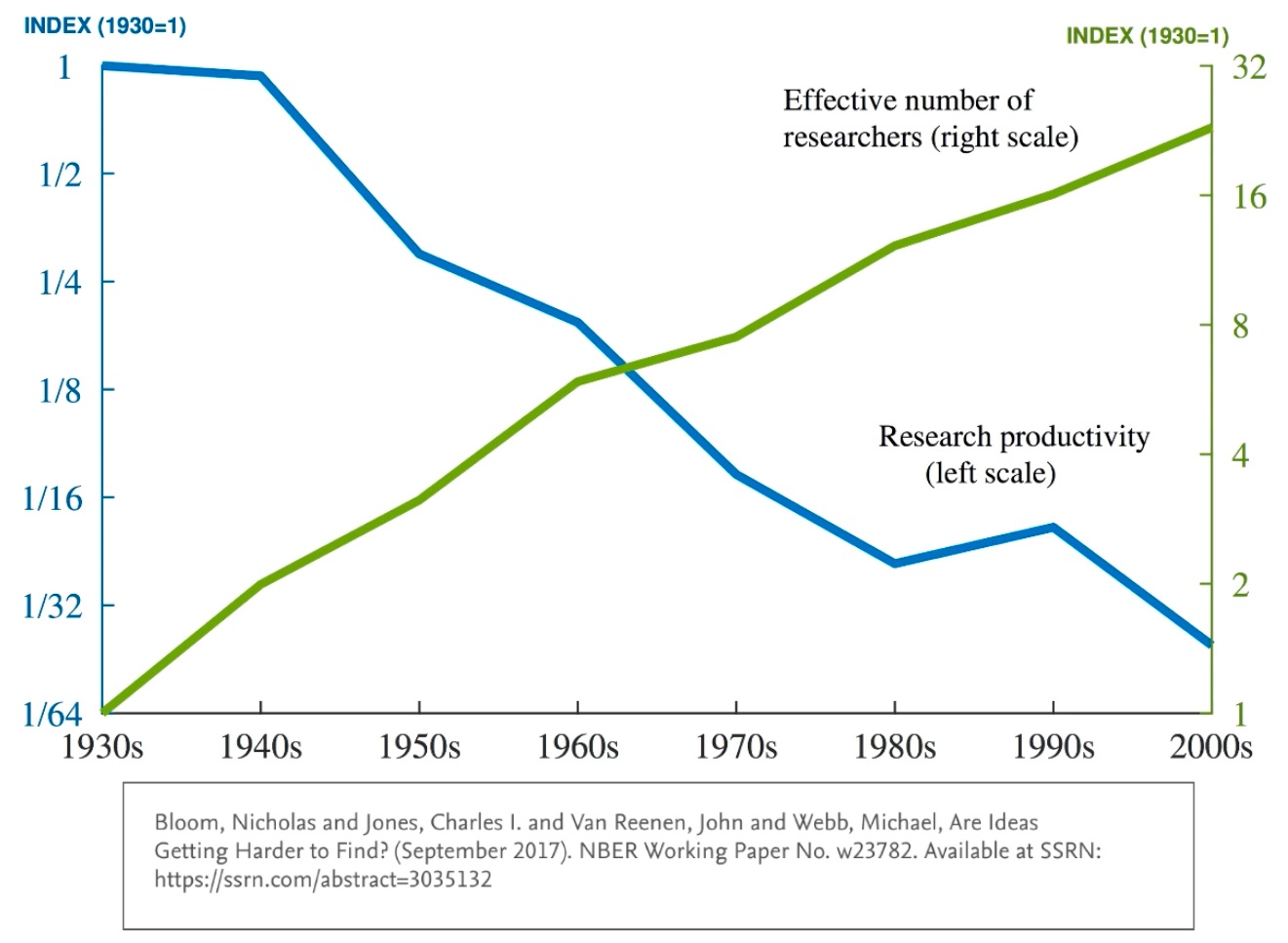
Good ideas are getting harder to find. That’s not a quip. It’s been studied. The number of researchers in the U.S. is increasing. But their productivity is declining. We aren’t innovating at the rate we’re investing in it.
The Collaboration Problem
We all accept that innovation needs good collaboration. It’s practically implicit. But we’ve got some bad habits.
We collaborate on a small scale and rely on luck: introductions by friends, conference happy-hours, reaching out to an article author and hoping to hear back. And we look for commonality, when it’s differences that spark new ideas.
“Networking is awkward, and humans don’t like it,” remarks Shannan Callies, an event organizer for many years and one of my colleagues at Exaptive. She has overseen events where hundreds of PhDs, researchers, clinicians, and other scientists gathered around a specific purpose. “One of the greatest challenges is making sure the right people get connected,” she reports.
But it doesn’t end there. Once we connect, we’ve got to actually work together. Dr. Alicia Knoedler, who is Executive Associate Vice President for Research at the University of Oklahoma, observes: “It’s not just ‘here’s a problem, and here’s a chemist trying to solve the problem.’ It’s ‘here’s a problem’ and there’s people from art, chemistry, engineering and psychology, all on a team together to address this problem in very unique ways.”
Meanwhile, expertise are getting more specialized, which has efficiency gains in established pipelines, but it stands in the way of innovative collaboration. The collaboration challenge will get more acute as time goes on.
Sadly, faced with that challenge, our best collaboration often arrives too late and remains too superficial. We tend to talk about our shared challenges intermittently and casually, instead of making it a central tenet of the work. “There’s a difference between all the researchers thinking independently about the problem and then coming together to figure it out, versus ‘what is interesting about this problem when we all think about it together?’ And then, ‘let’s figure out a different way of approaching it together,’” remarks Alicia.
The myth of the lone genius is debunked. Many grants even have stipulations requiring collaboration. No innovator is actually a solitary mad scientist. But team science, as it is, could drive us mad.
The Impact of Scale
Increasing the scale of our interactions is an important first step, because when it comes to innovation scale matters. Cities produce more intellectual property per person than towns. The concentration of people and resources disproportionately impacts innovation for the better. Metrics like crime and income scale linearly with population. Innovation, however, has increasing returns with scale.
Part of the explanation is friction, which can be a good thing. Put a million people or so in a small area, and you’ll get some friction. Some of it is unpleasant and counterproductive, like packed subways and long lines. Some of it is fortuitous and productive, like when people meet at conferences or at a coffee shop.
So there are more researchers than ever. How do we capitalize? We’ve got to get them in the same “city,” a digital city. Most software aims to reduce any and all friction, e.g. how can a customer complete a purchase as quickly as possible, how can a viewer find the media they like as easily as possible. But, as digital urban planners, we can deliberately create some beneficial friction to capitalize on scale for purposes of innovation. (Any digital urban planners out there?)
Collect Data About Actual Work, not Just Labels
So we want to generate productive friction from a concentration of people. What data do we use? It turns out we need more than job titles and department names. The crux is analyzing what people are actually working on.
At Exaptive, we’ve dubbed this artifact-based collaboration. An artifact of someone’s work can be anything created by a human, tangible or intangible, e.g. articles, code, techniques, hypotheses, datasets. This is their actual work, much more so than their personal attributes, like their job title or what department they work in. Artifacts say way more about what they need or what they can offer in an impactful collaboration.
This approach is a departure from the attribute-based collaboration we’re used to in environments like LinkedIn, e.g. “This group of accountants is recommended for you because you say you are an accountant.” Attributes are just proxies for what we’re actually doing and whether we ought to collaborate.
With data about work artifacts, we can make better collaboration suggestions. Here’s a simple example from a medical research community. “We suggest you collaborate with [researcher] because they are looking at biomarkers and you are researching drug efficacy, and the data you’re both using have similar structures.”
When two people are prepared with information about the qualities and the assets they bring to a project, they quickly become productive. Here’s a TEDx talk exploring the approach in greater detail.
Celebrate Difference
We’re used to getting matched or making connections based on similarity. While online: “If you like X, you’ll like Y.” While networking: “You work on that too! Great, let’s talk.” Similarity creates close connections. But it’s the weak ties that have a big impact.
Then again, the absence of any commonality makes it too difficult or impossible to collaborate. So finding the optimal distance for productive collaboration is the trick.
The right algorithm has an immediate impact. We tried it in analog -- a 30-minute workshop with an insurance company. Here’s a 1 minute video about what happened.
With software, we can do it faster and at scale. My colleague Frank Evans, a data scientist, explains: “The algorithms balance the similarities...So while the individuals may be connected by some things they have in common, they’re suggested for a team because their differences complement the strengths of the other members within the context of the common purpose.”
Having too little in common leads to a low score, but having too much in common also leads to a low score. The key to innovation is not just to maximize overlap. It’s to have the right commonality combined with the right amount of complementary differences.
These network diagrams compare a low scoring team with a high scoring team.
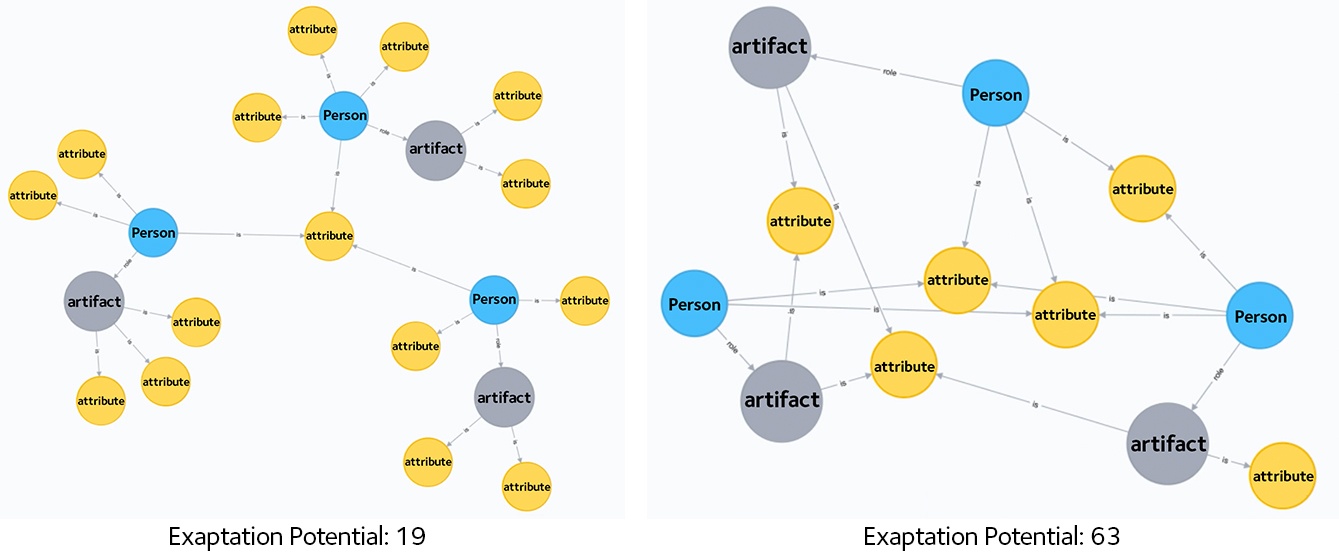
The low scoring team grows around one central commonality. In person it may feel like a strong team, but it’s actually a delicate snowflake, held together by one attribute.
The high scoring team has some commonalities and differences. It’s formed by a more resilient structure, which also happens to be more likely to lead to an innovation.
Planning Serendipity
A physician and an astronomer met at cocktail party. (It sounds like the beginning of a joke, but this is a true story.) In the course of conversation, the physician described the way MRI machines create images of the irregularly shaped human brain. The astronomer had an aha-moment: “Nebulae are irregularly shaped, but I’m just looking at them in the form of raw data!” They tried some astronomy data in some MRI software and the result is now the Harvard Astronomical Medicine Project.
Cool story, but it emphasizes how much we leave up to fate. Networking is mostly luck. You go someplace to meet a lot of people with the hope that some of your conversations are useful, just like you stand on a busy street to stack the odds in favor of catching a cab.
It doesn’t have to be left up to luck though. Just like an app can make finding a ride so easy that it’s more like having a personal driver than “catching” a cab, productive collaboration can be orchestrated, such that it’s more like having a personal muse than hoping to meet new people.
At Exaptive, we actually score suggestions based on what we call “exaptation potential.” Exaptation, in the innovation context, is the act of repurposing an idea from one field to another. The term was, ironically, exapted from a different field, evolutionary biology, and it’s gaining popularity as a model for innovation.
We’re measuring the potential of new perspective brought from one field to create a new and impactful idea in another. Then we’re facilitating the exchange, instead of leaving it to serendipity.
A Mini Case Study
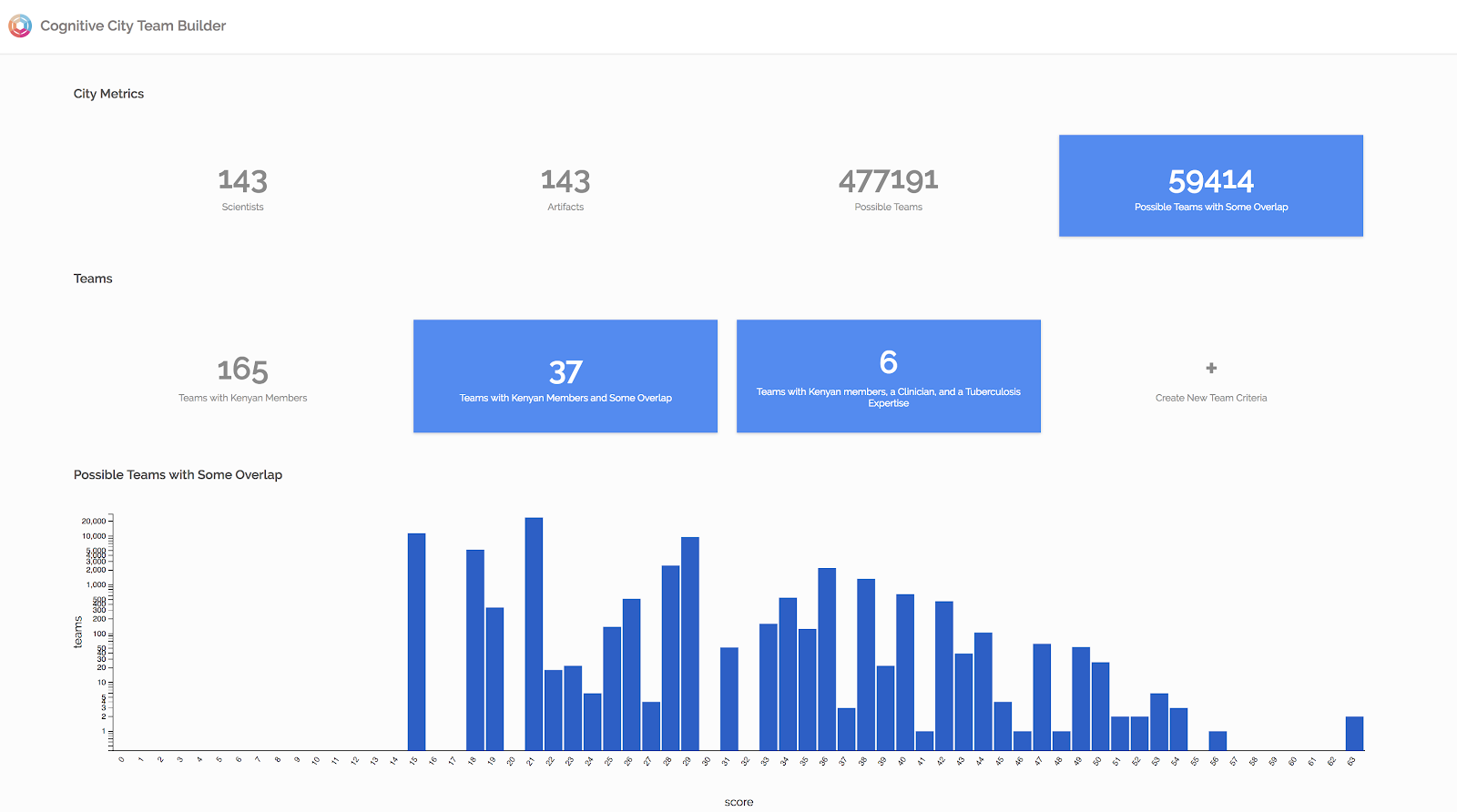
We set up a digital community (what we call a Cognitive City) for a group of about 150 doctors, researchers, and clinicians, who participated in a one-year, 20- to 35-person cohort in a program that ran for seven years. The participants have different specialties, researched in studies with diverse regional and topical foci, and they currently live all over the world. The director of the program was interested in finding the best three-person team to solve a health problem in a specific region.
If you were to create a three-person team from a group of 143 individuals, you’d have 477,191 options to choose from. Even if everyone were in the same room, it would be almost impossible to find the best team by trial and error. Serendipity would rule.
Grouping people by some personal attributes, like their job title or speciality, helps a little but not enough. There are 59,414 possibilities remaining.
But with the approach I’ve described -- analyzing work artifacts and celebrating difference -- the organization focused in on 6 potential collaborations with the right similarities and differences in location and competency.
Related Posts:
Use Data, Technology, and Intention to Optimize Team Building
Cowboys and Inventors: The Myth of the Lone Genius
Comments